
While people were busy talking about OpenAI’s DALL-E & ChatGPT, Microsoft quietly introduced its speech-synthesizing tool, VALL-E. Just recently, Microsoft announced a new text-to-speech (TTS) AI model called VALL-E that simulates a person’s voice with just a three-second-long audio sample.
Speech synthesis is not a new concept. In fact, voice replication has been a subject of intense research. Over the past few years, researchers have developed and tested speech synthesis solutions.
The results have been so effective that startups like WellSaid and Papercup began providing authorized voice reproductions of actors and celebrities as a service.
So, what makes VALL-E different from other TTS models? In this article, we discuss what VALL-E is and why it is garnering so much attention.
What is Microsoft VALL-E?
Microsoft VALL-E is a TTS model that is designed to generate human-like speech, with a focus on making the model expressive and emotional. It has been trained on a diverse dataset of voices, and it’s able to generate speech with a wide range of emotions, intonations, and speaking styles. A free demonstration is available on GitHub.
How does VALL-E Work?
Despite the fact that VALL-E’s capabilities are not as novel as you may think, Microsoft did use a unique approach to speech rendering.
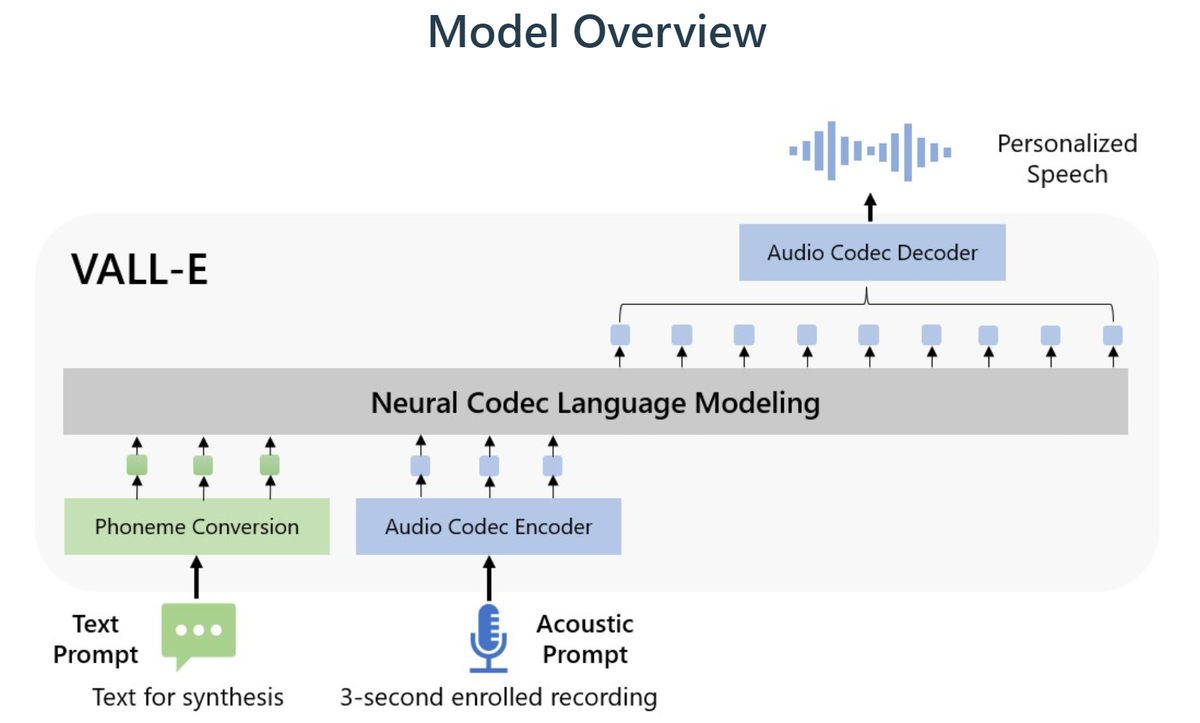
Built off and around a technology called EnCodec (by Meta), Microsoft’s VALL-E is a ‘neural codec language model’ that delivers high-quality text-to-speech voice rendering. What is really interesting about VALL-E is that it only requires a three-second-long audio clip in order to synthesize natural speech and mimic a human.
Once VALL-E finishes analyzing the way a person sounds, it saves this information into discrete voice ‘tokens’ as explained by Microsoft in their VALL-E research paper. Whenever VALL-E reads a text prompt, it does this in a voice that closely resembles the one it recently listened to.
 Source: https://valle-demo.github.io/
Source: https://valle-demo.github.io/
What Makes VALL-E Different from Other Text-to-speech Models?
What makes VALL-E different is the way it synthesizes speech. Unlike other TTS AI models that generate speech by manipulating sound waveforms, VALL-E generates discrete audio signals (called audio codec codes) from text and auditory prompts.
VALL-E was also trained on more than 60,000 hours of English speech from 7,000 speakers – this is 100 times more training data than previously used in this field. The huge data set on which VALL-E was trained explains why it is so apt at mimicking natural speech.
Use Cases of VALL-E
VALL-E was only recently released, however, many use cases are being investigated across healthcare, gaming, content creation, and entertainment.
Becoming a Voice for the Voiceless: VALL-E in the Medical Sector
Speech impairment may become a thing of the past if VALL-E can be effectively leveraged in the medical sector.
The VALL-E text-to-speech method offers a way out for people who have lost their ability to speak at some point in life. If someone who suffers from dysarthria has previous voice recordings, this will be enough for VALL-E to learn and reproduce their natural speech. The medical community is optimistic about the fact that VALL-E can generate speech for people with visual impairment or language disorders.
VALL-E Automating Voice-overs in the Gaming Industry
VALL-E is an exciting development for those working in the gaming industry, especially those looking at keeping costs low and making operations efficient.
Since VALL-E synthesizes natural speech with higher speaker accuracy than past methods, this means the technology could replace voice actors to record in-game character voices. Just select a voice recording from your existing voice repositories and have VALL-E listen to it. The next time you need the same in-game character’s voice, let VALL-E read the story dialogue for you. And the finesse with which it will mimic the voice artist will amaze you – you can thank Microsoft later.
Learn New Languages and Perfect a Dialect with VALL-E
The high speaker accuracy achieved by VALL-E means language learning has become as easy as listening to VALL-E as it reads written text for you. This will also allow language learners to select a particular dialect to learn, opening up language learning options significantly. Users will only require a few recordings of professional speakers conversing in the selected language and dialect and VALL-E will reproduce the voice perfectly.
Let Your Stories Speak for Themselves via VALL-E
If you were getting fed up with artificial bots like Microsoft David reading your written content for you, then it’s time to switch to a voice that feels more human, more YOU!
Why not let VALL-E listen to a bit of your voice so that it may narrate your blog content or article in your style, giving your stories your own voice by integrating VALL-E with your website?
Once VALL-E has picked up how you sound, it will take care of everything else. All you have to do is craft some great content and let VALL-E do the talking.
VALL-E in Entertainment and Music Industry
If VALL-E were to replace jobs in the future, they would likely be in the entertainment industry, specifically for voice actors.
Considering the speed and accuracy with which VALL-E reproduces human voices, voice acting may soon become extinct. From in-game character voices to cartoons to video and voice productions – every sector that uses voice and human speech may soon be filled with VALL-E and similar TTS models.
Similar to how DALL-E caused a massive uproar in the image art industry, we might soon see well-known performers and singers with their legal counsel demanding rights to their distinctive voices.
These are just a few of the use cases that businesses may find useful. However, just like Chat GPT seeing new use cases every day, the capabilities of VALL-E will surely be extended to other use cases as people begin experimenting with the technology.


